In the last month or two we’ve made some good progress with getting additional parts of the SpokenMedia workflow into a working state.
Here’s a workflow diagram showing what we can do with SpokenMedia today.
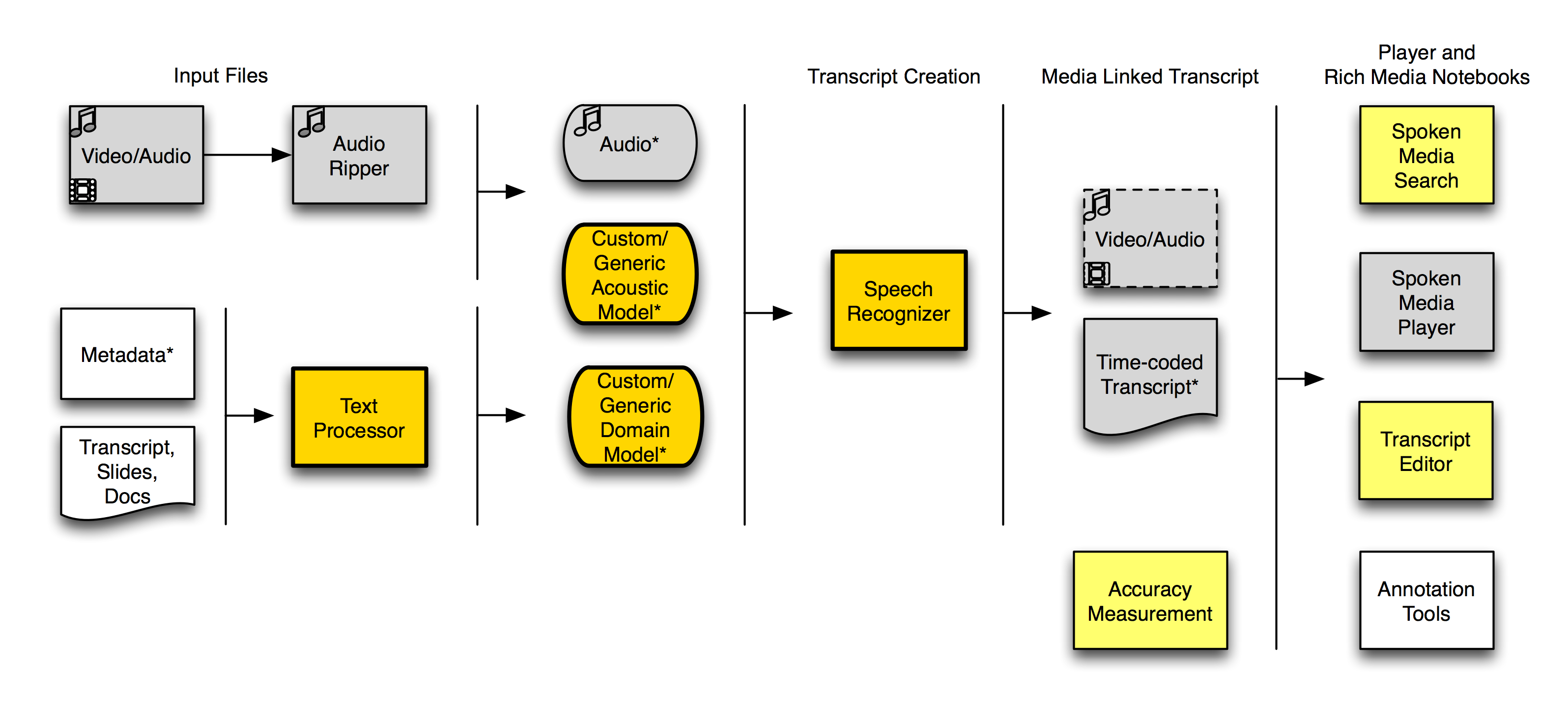
SpokenMedia Workflow, June 2010
(The bright yellow indicates features working in the last two months, the gray indicates features we’ve had working since December 2009, and the light yellow indicates features on which we’ve just started working.)
To recap, since December 2009, we’ve been able to:
- Rip audio from video files and prepare it for the speech recognizer.
- Process the audio through the speech recognizer locally within the SpokenMedia project using domain and acoustic models.
- Present output transcript files (.WRD) through the SpokenMedia player.
Recently, we’ve added the ability to:
- Create domain models (or augment existing domain models from files.
- Create unsupervised acoustic models from input audio files. (Typically 10 hours of audio by the same speaker are required to create “good” acoustic model–certainly for American’s speaking English. We’re still not sure how well this capability will allow us to handle Indian-English speakers.)
- Use a selected domain or acoustic model from a pre-existing set, in addition to creating a new one.
- Process audio through an “upgraded” speech recognizer, using the custom domain and acoustic models. Though this recognition is being performed on Jim Glass’ research cluster.
We still have a ways to go–we still need to better understand the potential accuracy of our approach. The critical blocker is now a means to compare a known accurate transcript with the output of the speech recognizer (it’s a matter of transforming existing transcripts into time-aligned ones of the right format). And then there are the two challenges of automating the software and getting it running on OEIT servers (we’ve reverted to using Jim Glass’ research cluster to get some of the other pieces up and running).
