During our trip to India in early January 2010, Brandon Muramatsu, Andrew McKinney and Vijay Kumar met with Prof. Mangala Sunder and the Indian National Programme on Technology Enhanced Learning (NPTEL) team at the Indian Institute of Technology-Madras.
The SpokenMedia project and NPTEL are in discussions to bring the automated lecture transcription process under development at MIT to NPTEL to:
- Radically reduce transcription and captioning time (from 26 hours to as little as 2 hours).
- Improve initial transcription accuracy via a research and development program.
- Improve search and discovery of lecture video via transcripts.
- Improve accessibility of video lectures for the diverse background of learners in India, and worldwide, via captioned video.
NPTEL, the National Programme on Technology Enhanced Learning, is a program funded by the Indian Ministry for Human Resource Development and a collaboration of a number of participating Indian Institutes of Technology. As part of Phase I, they have published approximately 4,500 hours of lecture videos in engineering courses that comply with the model curriculum suggested by All India Council for Technical Education. In an even more ambitious Phase II, they plan to add approximately 40,000 additional hours of lecture video for science and engineering courses.
The current NPTEL transcription and captioning process is labor and time intensive. During our discussions, we learned that it takes approximately 26 hours on aveage to transcribe and caption a single hour of video. Even with the initial hand transcription, they are averaging 50% accuracy.
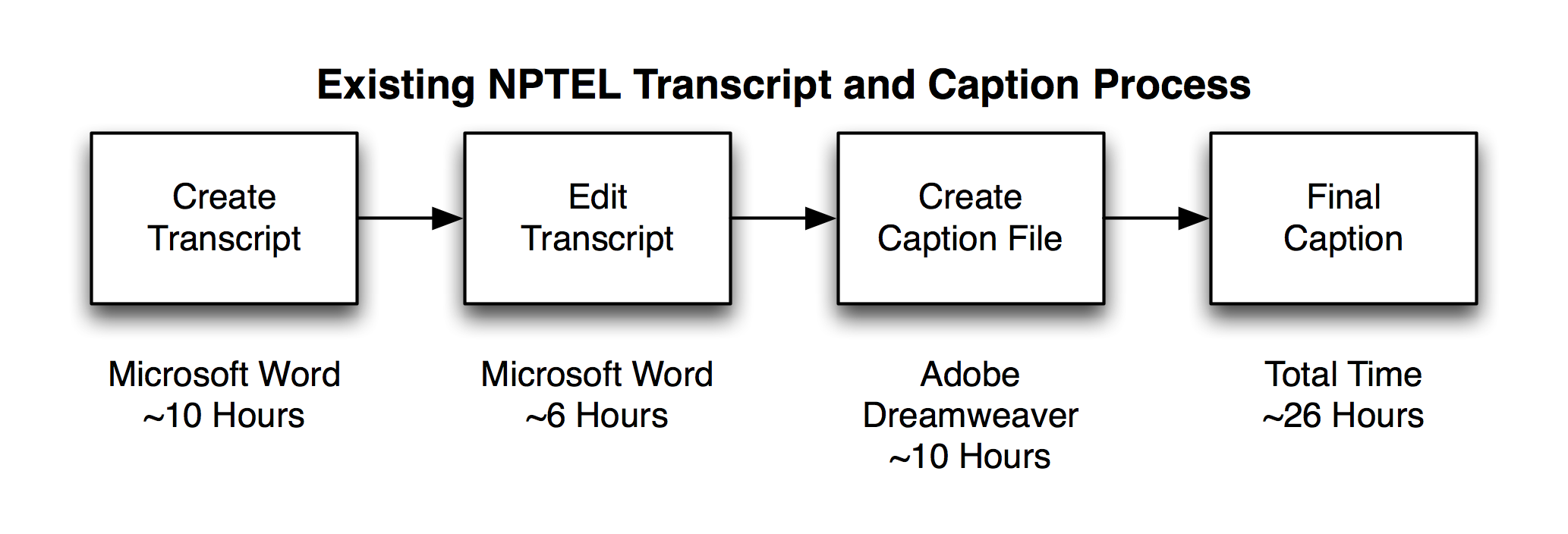
NPTEL Current Transcription and Captioning Process
We discussed using the untrained SpokenMedia software to improve the efficiency of this initial process. Our initial experiments suggest that the untrained recognizer can achieve 40-60% accuracy, which is in the same range as the current NPTEL hand process. Thus we propose replacing the hand transcription and captioning steps with a two step recognition and editing process. Using a single processor, the recognition step takes on the order of 1.5 hours per 1 hour of video. Using this estimate coupled with the existing editing time in use at NPTEL, the overall process might be reduced from 26 hours to approximately 10 hours.
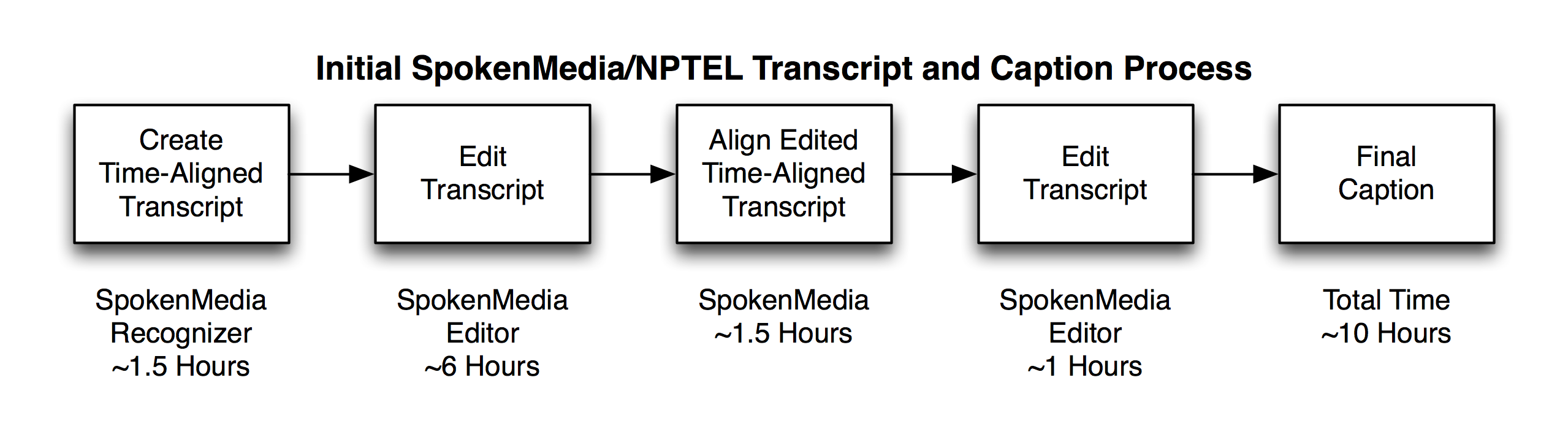
Initial Improved NPTEL Transcription and Captioning Process
And we discussed initiating an applied research and development project to create baseline acoustic (speaker) models for Indian English for use in the automated lecture transcription process, with the goal of improving the automated transcription accuracy to the same range of American English transcription (as high as 80-85% accuracy). The use of improved acoustic models and parallizing the recognition process might reduce the total transcription time to approximately 2 hours.

Goal NPTEL Transcription and Captioning Process
