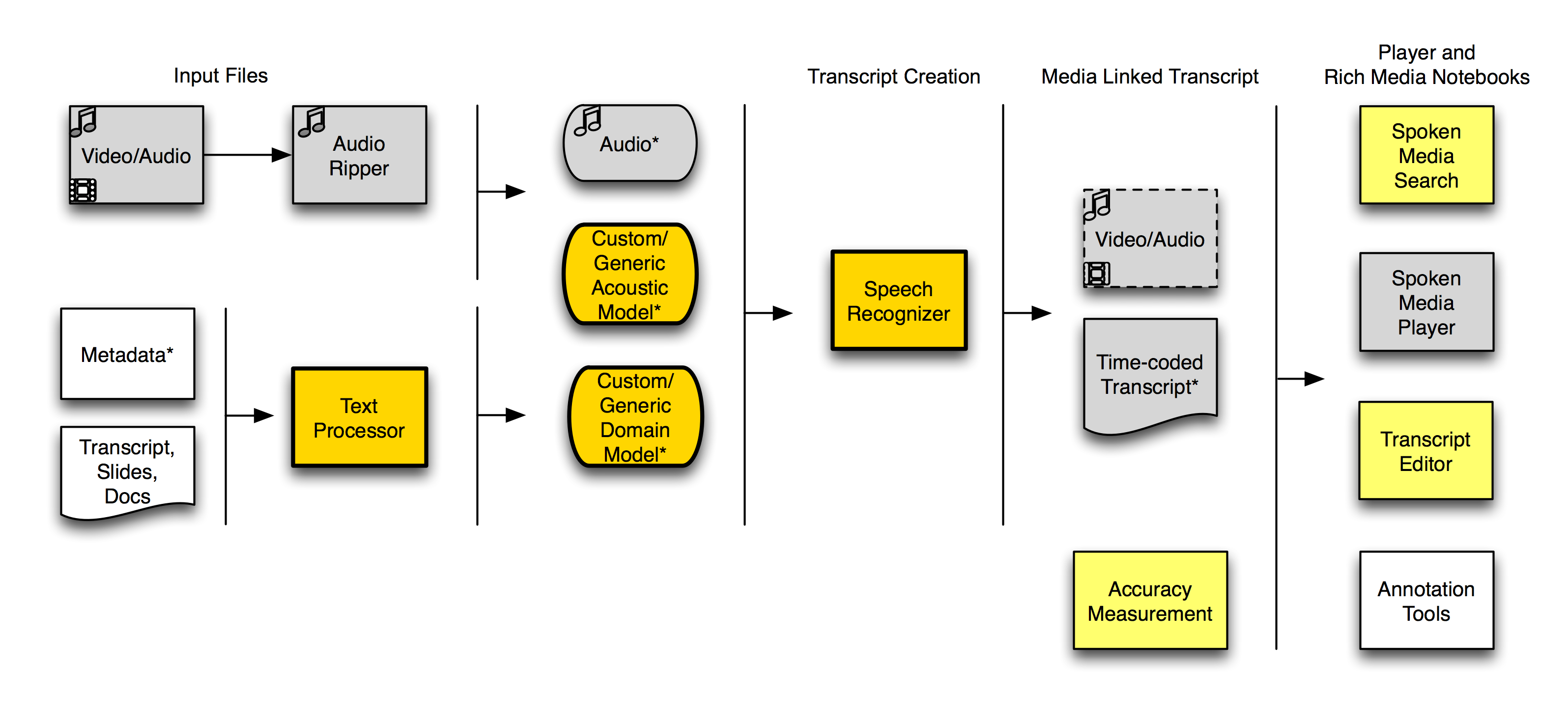
Here’s a workflow diagram I put together to demonstrate how we’re approaching the problem of searching over the transcripts of multiple videos and ultimately returning search results that maintain time-alignment for playback.
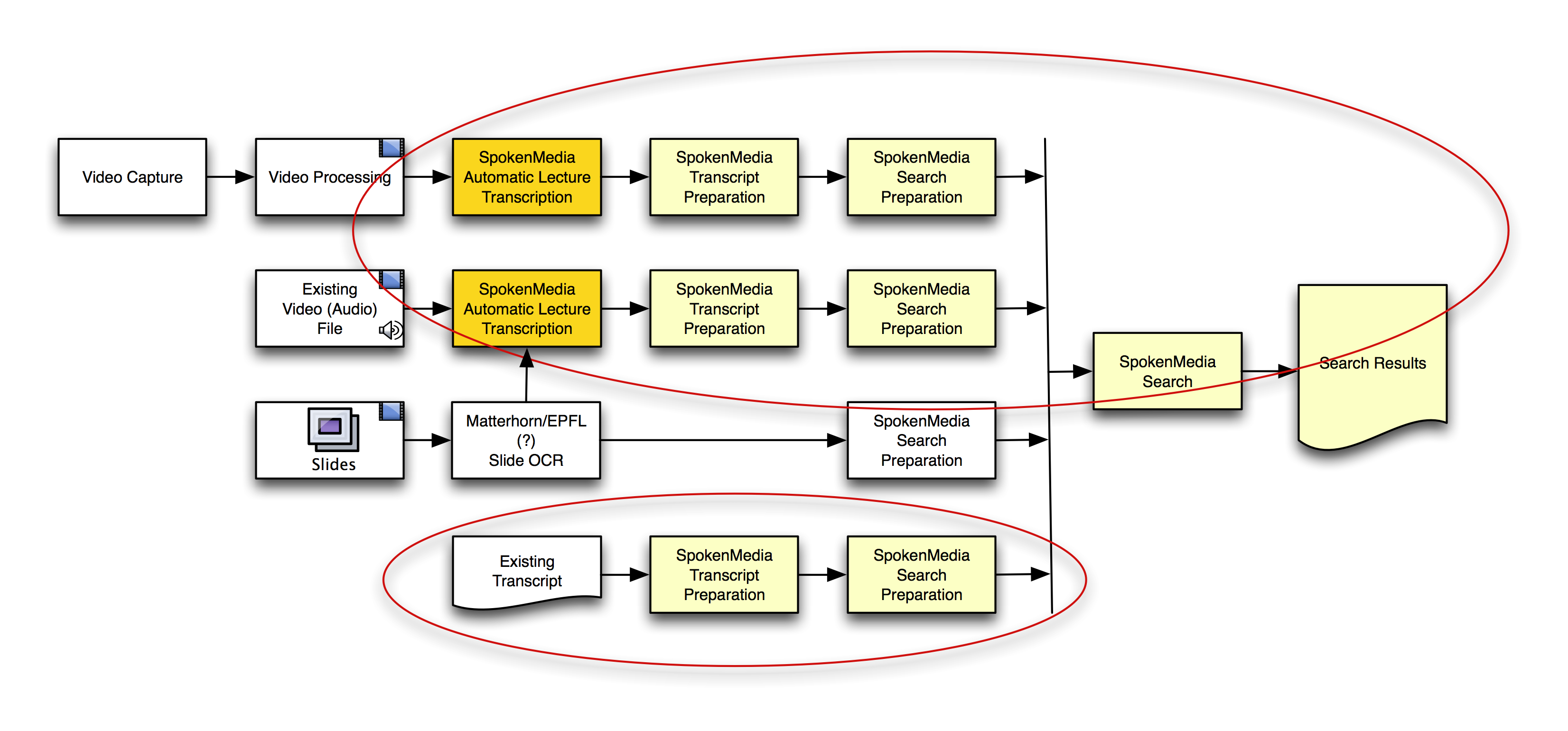
Source: Brandon Muramatsu
Preparing Transcripts for Search Across Multiple Videos
You’ll notice I included using OCW on lecture slides to help in search and retrieval–this is not an area we’re currently focusing on, but we have been asked about it. A number of researchers and developers have looked at this area–if/when we include it, we’d work with folks like Matterhorn (or perhaps others) to integrate the solutions that they’ve implemented.