MIT’s OpenCourseWare uses MIT’s Google Search Appliance (GSA) to search its content. MIT supports customization of GSA results through XSL transformation. This post describes how we plan to use GSA to search lecture transcripts and return results containing the lecture videos that the search terms appear in. Since OCW publishes static content, it doesn’t incorporate an integral search engine. Search is provided through Continue Reading
August 12, 2010
How Google Translate Works
Google posted a high level overview of how Google Translate works. Source: Google
Continue reading... August 6, 2010
Running the Baseline Recognizer
The software that processes lecture audio into a textual transcript is comprised of a series of scripts that marshall input files and parameters to a speech recognition engine. Interestingly, since the engine is data driven, its code seldom changes; improvements in performance and accuracy are achieved by refining the data it uses to perform its […]
Continue reading... July 28, 2010
An interesting hack from Yahoo! Openhack India
Sound familiar? Automatic, Real-time close captioning/translation for flickr videos. How? We captured the audio stream that comes out to speaker and gave as input to mic. Used Microsoft Speech API and Julius to convert the speech to text. Used a GreaseMonkey script to sync with transcription server(our local box) and video and displayed the transcribed […]
Continue reading... July 24, 2010
Converting .sbv to .trans/continuous text
As a step in comparing the output from YouTube’s Autocaptioning, we need to transform their .sbv file into something we can use in our comparison tests (a .trans file). We needed to strip the hours out of the timecode, drop the end time, and bring everything to a single line. Update: It turns out we […]
Continue reading... July 19, 2010
Caption File Formats
There’s been some discussion on the Matterhorn list recently about caption file formats, and I thought it might be useful to describe what we’re doing with file formats for SpokenMedia. SpokenMedia uses two file formats, our original .wrd files output from the recognition process and Timed Text Markup Language (TTML). We also need to handle […]
Continue reading... June 21, 2010
Towards cross-video search
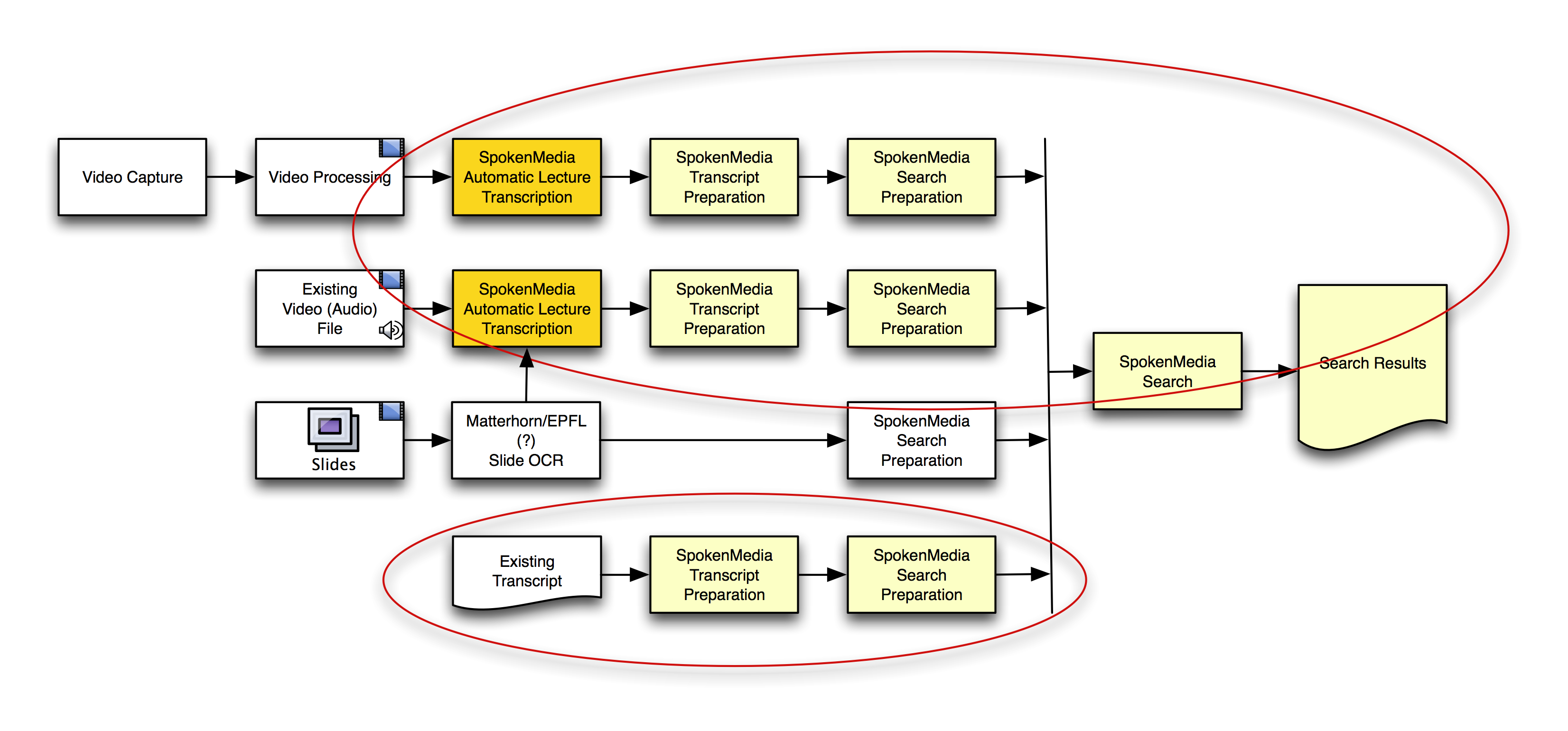
Here’s a workflow diagram I put together to demonstrate how we’re approaching the problem of searching over the transcripts of multiple videos and ultimately returning search results that maintain time-alignment for playback. You’ll notice I included using OCW on lecture slides to help in search and retrieval–this is not an area we’re currently focusing on, […]
Continue reading... June 17, 2010
Making Progress
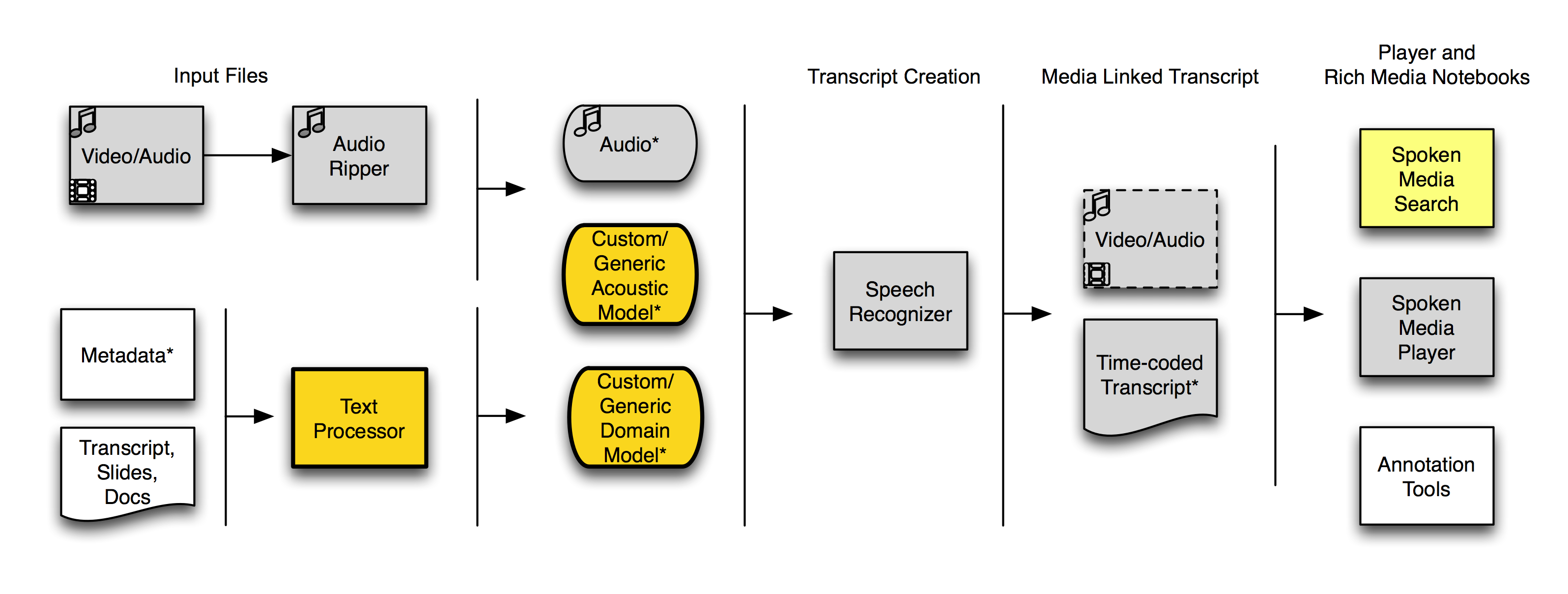
In the last month or two we’ve made some good progress with getting additional parts of the SpokenMedia workflow into a working state. Here’s a workflow diagram showing what we can do with SpokenMedia today. (The bright yellow indicates features working in the last two months, the gray indicates features we’ve had working since December […]
Continue reading... June 16, 2010
Using Lucene/Solr for Transcript Search
Overview In any but a trivial implementation, searching lecture transcripts presents challenges not found in other search targets. Major among them is that each transcript word requires its own metadata (start and stop times). Solr, a web application that derives its search muscle from Apache Lucene, has a query interface that is both rich and […]
Continue reading...