MIT’s OpenCourseWare uses MIT’s Google Search Appliance (GSA) to search its content. MIT supports customization of GSA results through XSL transformation. This post describes how we plan to use GSA to search lecture transcripts and return results containing the lecture videos that the search terms appear in. Since OCW publishes static content, it doesn’t incorporate an integral search engine. Search is provided through Continue Reading
June 21, 2010
Towards cross-video search
Here’s a workflow diagram I put together to demonstrate how we’re approaching the problem of searching over the transcripts of multiple videos and ultimately returning search results that maintain time-alignment for playback.
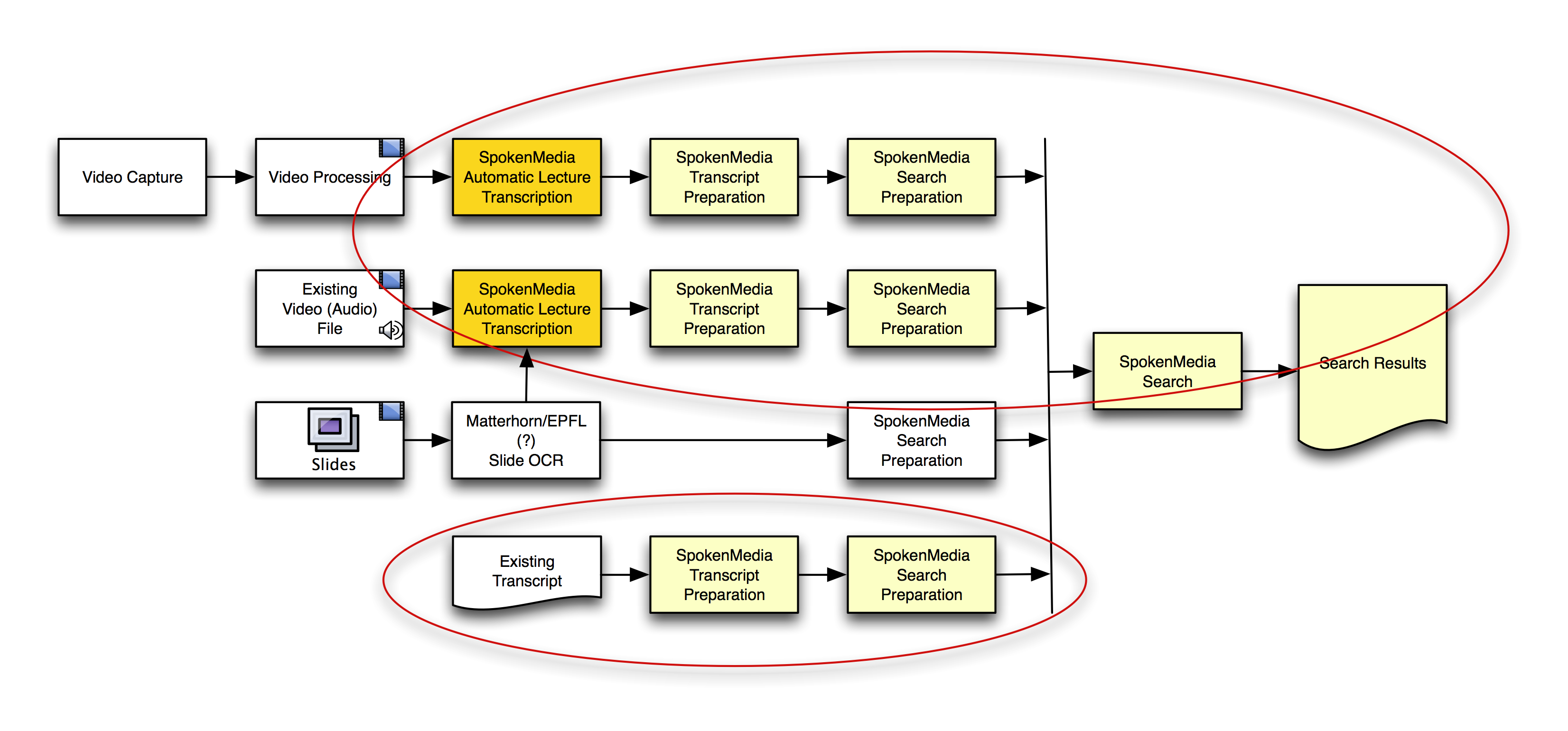
Source: Brandon Muramatsu
Preparing Transcripts for Search Across Multiple Videos
You’ll notice I included using OCW on lecture slides to help in search and retrieval–this is not an area we’re currently focusing on, but we have been asked about it. A number of researchers and developers have looked at this area–if/when we include it, we’d work with folks like Matterhorn (or perhaps others) to integrate the solutions that they’ve implemented.
June 16, 2010
Using Lucene/Solr for Transcript Search
Overview
In any but a trivial implementation, searching lecture transcripts presents challenges not found in other search targets. Major among them is that each transcript word requires its own metadata (start and stop times). Solr, a web application that derives its search muscle from Apache Lucene, has a query interface that is both rich and flexible. It doesn’t hurt that it’s also very fast. Properly configured, it provides an able platform to support lecture transcript searching. Although Solr is the server, the search itself is performed by Lucene so much of the discussion will address Lucene specifically. The integration with the server will be discussed in a subsequent posting.
Objective
We want to implement an automated work flow that can take a file that contains all the words spoken in the lecture, along with their start and stop times and persist them into a repository that will allow us to:
- search all transcripts for a word, phrase, or keyword with factored searches, word-stemming, result ranking, and spelling correction.
- Have the query result include metadata that will allow us to show a video clip mapping the word to the place in the video where it is uttered.
- Allow a transcript editing application to modify the content of the word file, as well as the time codes, in real-time.
- Dependably maintain mapping between words and their time codes.
