MIT’s OpenCourseWare uses MIT’s Google Search Appliance (GSA) to search its content. MIT supports customization of GSA results through XSL transformation. This post describes how we plan to use GSA to search lecture transcripts and return results containing the lecture videos that the search terms appear in. Since OCW publishes static content, it doesn’t incorporate an integral search engine. Search is provided through Continue Reading
August 12, 2010
How Google Translate Works
August 6, 2010
Running the Baseline Recognizer
The software that processes lecture audio into a textual transcript is comprised of a series of scripts that marshall input files and parameters to a speech recognition engine. Interestingly, since the engine is data driven, its code seldom changes; improvements in performance and accuracy are achieved by refining the data it uses to perform its tasks.
There are two steps to produce the transcript. The first creates an audio file in the correct format for speech recognition. The second processes that audio file into the transcript.
July 24, 2010
Converting .sbv to .trans/continuous text
As a step in comparing the output from YouTube’s Autocaptioning, we need to transform their .sbv file into something we can use in our comparison tests (a .trans file). We needed to strip the hours out of the timecode, drop the end time, and bring everything to a single line.
Update: It turns out we needed a continuous text file. So these have been updated accordingly.
July 19, 2010
Caption File Formats
There’s been some discussion on the Matterhorn list recently about caption file formats, and I thought it might be useful to describe what we’re doing with file formats for SpokenMedia.
SpokenMedia uses two file formats, our original .wrd files output from the recognition process and Timed Text Markup Language (TTML). We also need to handle two other caption file formats .srt and .sbv.
There is a nice discussion of the YouTube format at SBV file format for Youtube Subtitles and Captions and a link to a web-based tool to convert .srt files to .sbv files.
We’ll cover our implementation of TTML in a separate post.
Continue Reading
June 21, 2010
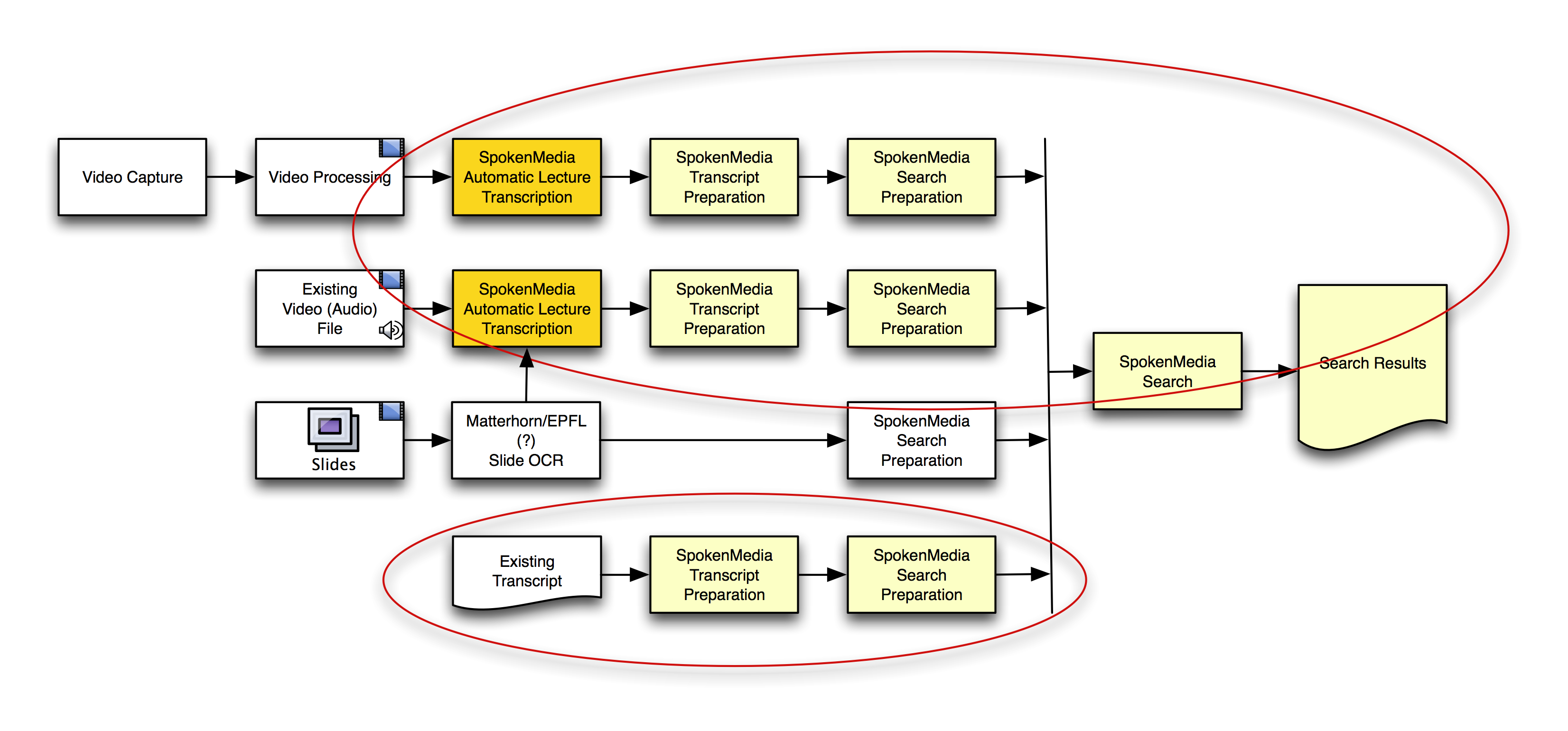
Towards cross-video search
Here’s a workflow diagram I put together to demonstrate how we’re approaching the problem of searching over the transcripts of multiple videos and ultimately returning search results that maintain time-alignment for playback.
Source: Brandon Muramatsu
Preparing Transcripts for Search Across Multiple Videos
You’ll notice I included using OCW on lecture slides to help in search and retrieval–this is not an area we’re currently focusing on, but we have been asked about it. A number of researchers and developers have looked at this area–if/when we include it, we’d work with folks like Matterhorn (or perhaps others) to integrate the solutions that they’ve implemented.
June 17, 2010
Making Progress
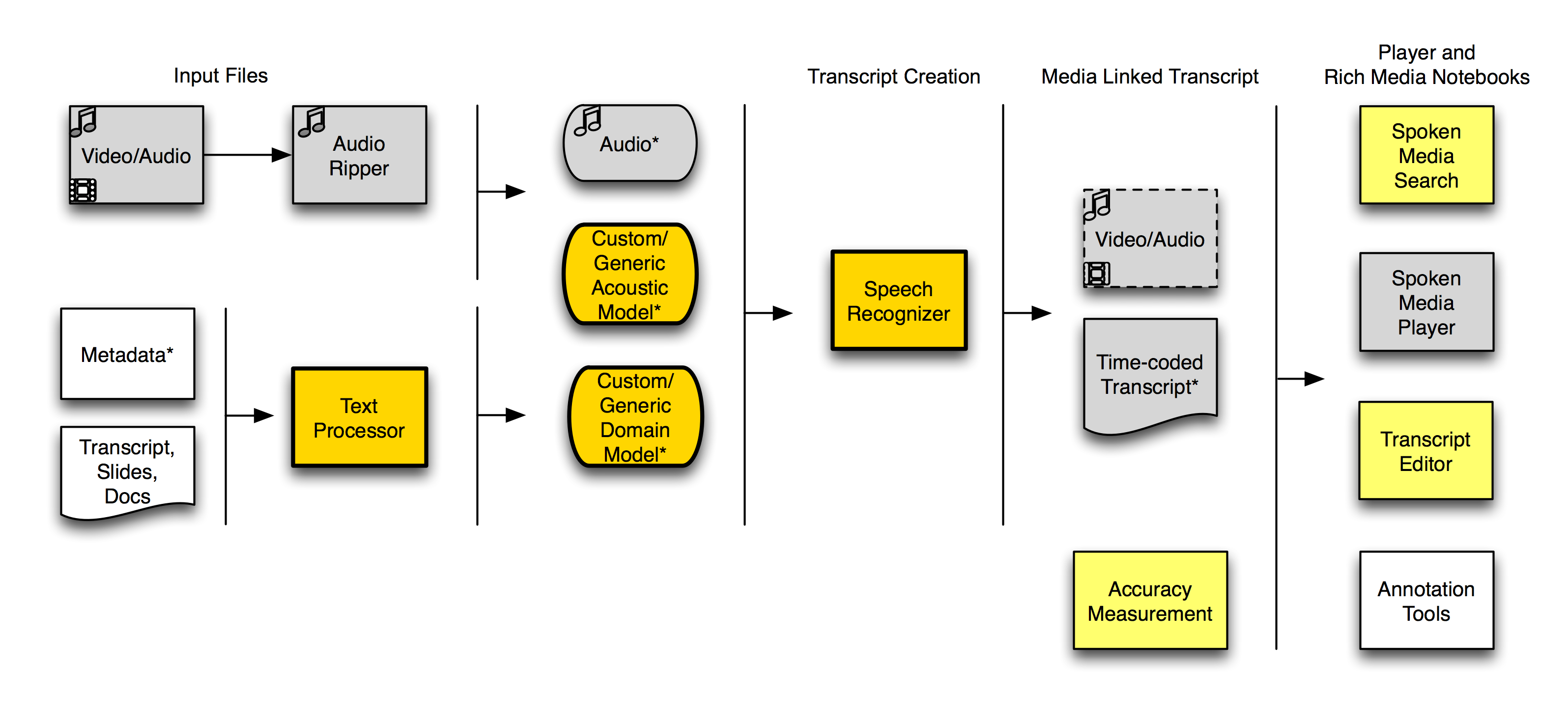
In the last month or two we’ve made some good progress with getting additional parts of the SpokenMedia workflow into a working state.
Here’s a workflow diagram showing what we can do with SpokenMedia today.
Source: Brandon Muramatsu
SpokenMedia Workflow, June 2010
(The bright yellow indicates features working in the last two months, the gray indicates features we’ve had working since December 2009, and the light yellow indicates features on which we’ve just started working.)
June 16, 2010
Using Lucene/Solr for Transcript Search
Overview
In any but a trivial implementation, searching lecture transcripts presents challenges not found in other search targets. Major among them is that each transcript word requires its own metadata (start and stop times). Solr, a web application that derives its search muscle from Apache Lucene, has a query interface that is both rich and flexible. It doesn’t hurt that it’s also very fast. Properly configured, it provides an able platform to support lecture transcript searching. Although Solr is the server, the search itself is performed by Lucene so much of the discussion will address Lucene specifically. The integration with the server will be discussed in a subsequent posting.
Objective
We want to implement an automated work flow that can take a file that contains all the words spoken in the lecture, along with their start and stop times and persist them into a repository that will allow us to:
- search all transcripts for a word, phrase, or keyword with factored searches, word-stemming, result ranking, and spelling correction.
- Have the query result include metadata that will allow us to show a video clip mapping the word to the place in the video where it is uttered.
- Allow a transcript editing application to modify the content of the word file, as well as the time codes, in real-time.
- Dependably maintain mapping between words and their time codes.
May 21, 2010
Packaging Stand-alone SM-Player
Overview
The stand-alone player allows users to view and search video transcripts without network access. Due to the technologies that the player uses, the stand-alone player requires a small web server to work. These instructions describe how to package a video, its associated transcripts, and its supporting files into a stand-alone sm-player. The package can be zipped into a single file, downloaded, unzipped, and run locally.
This package is what is downloaded when we publish a contributed video and its transcript.
Audience
This document is intended for those who will create these packages. A separate README describes how to deploy and run the package.
May 11, 2010
PageLayout as a step towards Rich Media Notebooks
During a meeting with our collaborators at ICAP, of the Universite de Lyon 1 in France, Fabien Bizot demonstrated the PageLayout Flash/Air app that he was working on for Spiral Connect.
When we launched the SpokenMedia project, we knew that we wanted to ultimately focus on how learners and educators use video accompanied by transcripts. Over the last year, we’ve focused on the automatic lecture transcription technology that was developed in the Spoken Lecture project–as a means to enable the notions of rich media notebook we had been discussing.
Fabien Bizot’s work with PageLayout may be the first step to a user interface learners and educators might use to interact with video linked with transcripts.